Empowering the Danish Language in the Digital Age¶
Welcome to the Danish Foundation Models (DFM) project, a pioneering initiative in the field of machine learning and natural language processing (NLP) dedicated to the Danish language. Our mission is to develop, maintain, and provide open access to high-quality foundation models tailored for Danish, promoting innovation and inclusivity in language technologies.
Read the paper
You can read more about the argument for Danish Language models in our publication.
Why Danish Foundation Models?¶
Bridging the Digital Language Divide¶
- Global Gap: The rise of large language models has transformed research and technology, but smaller languages like Danish risk falling behind both in development, evaluation and application.
- Local Focus: We combat this by focusing on the Danish language, ensuring that it is well-represented in the digital landscape.
- Broad Collaboration: Our project unites public and private institutions, ensuring high data quality and practical applicability of our models.
Our Objectives¶
- To develop and maintain state-of-the-art language models for Danish for applications within both text and speech.
- To extensively validate foundation models for Danish in a representative set of tasks.
- To maintain a high standard of documentation of models such as model cards [Mitchell et al., 2019] and datasheets [Gebru et al., 2021].
- To open-source not only the models but also all components required for reproducibility such as pre-processing, training, and validation code.
Open-source¶
Open-source Development with Privacy-Focused Data Handling¶
In our commitment to advancing open-source development, we strongly emphasise the ethical handling of data, particularly when it involves personally sensitive information or material under copyright. This ensures that we share as much as possible while protecting privacy.
To achieve this, our project is structured to differentiate between data that can be shared openly and that which cannot. This demarcation is documented through detailed datasheets and training logs, thereby ensuring transparency in our processes.
Additionally, we prioritise the security of the data during its processing and training phases. All data is stored on UCloud, a platform that upholds the recognised highest standards in information security management. This commitment to data security is exemplified by UCloud's adherence to ISO27001, a globally recognised standard, ensuring that our data handling practices meet rigorous international criteria. For more information on our security measures, please visit UCloud's security documentation.
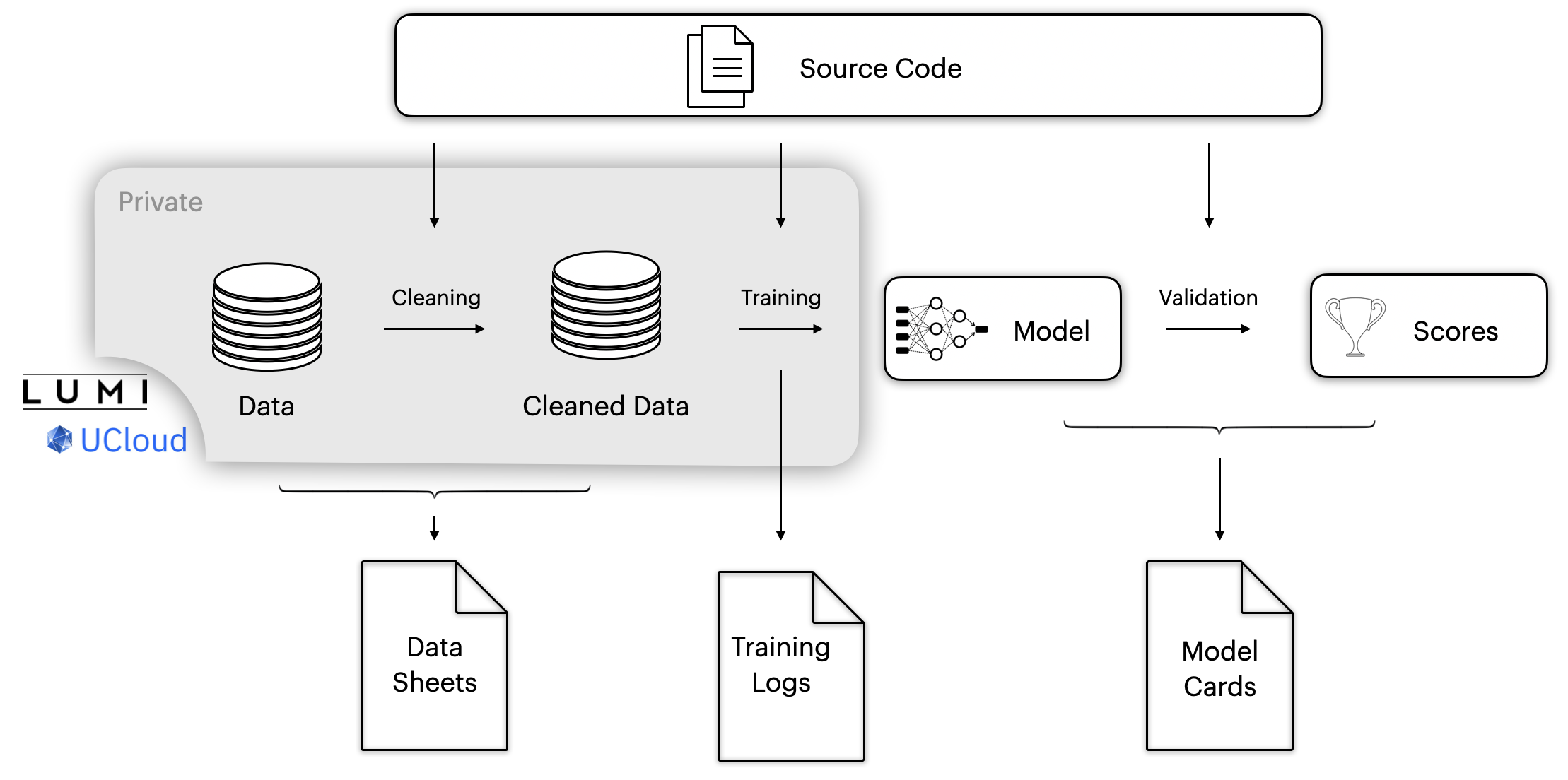
Contributions¶
Besides our models DFM has led to a series of positive open-source contributions, the following table include some of these contributions:
| Project | Contribution |
|---|---|
| Packages | |
| NLPDedup | A deduplication library derived from DFM's deduplication code |
| Code contributions | |
| TextDescriptives | Added heuristic quality measure for texts |
| dolma | Bugfixes and addition of taggers for filtering |
| Benchmarks | |
| ScandEval | Co-contributors have significant contributions to developing NLU and NLG benchmarks for Scandinavian and Germanic languages |
| Scandinavian Embedding Benchmark | The benchmark for evaluating Scandinavian embedding has been created as a part of DFM |
| Datasets | |
| m_arc, m_mmlu, m_hellaswag, m_truthfulqa | Translated versions of English datasets intended for model evaluation for these domains |
Improving the Danish Language Technology Landscape¶
The Danish Foundations models is a collaboration across Danish universities and research organizations. The project engages with data science communities and initiatives (Danish Data Science Community), to promote the development of Danish language tools. We continually gather information about how to improve the Danish language technologies and how to best support the community. If you want to highlight missing pieces in Danish NLP we invite you to open a thread on the forum stating the problems and potential solutions.
Contributors¶
The Core Team¶
Those with data access, who contribute to the project, including data management, model development, project management, and more.
From the Center for Humanities Computing at Aarhus University:
- Kenneth Enevoldsen (kenneth.enevoldsen@cas.au.dk)
- Marton Kardos (martonkardos@cas.au.dk)
- Jan Kostkan (jan.kostkan@cas.au.dk)
- Peter Vahlstrup (imvpbv@cc.au.dk)
- Per Møldrup-Dalum (per@cas.au.dk)
- Kristoffer Laigaard Nielbo (kln@cas.au.dk)
From the Alexandra Institute:
- Rasmus Larsen (rasmus.larsen@alexandra.dk)
- Dan Saattrup Nielsen (dan.nielsen@alexandra.dk)
- Andreas Nugaard Holm (andreas.holm@alexandra.dk)
- Kristian Nørgaaard Jensen (kristian.n.jensen@alexandra.dk)
- Torben Blach (torben.blach@alexandra.dk)
- Jens Kaas Benner (jens.benner@alexandra.dk)
From the Center for Machine Learning at the University of Southern Denmark:
- Peter Schneider-Kamp (petersk@imada.sdu.dk)
- Lukas Galke (galke@imada.sdu.dk)
- Andrea Blasi Núñez (abln@mmmi.sdu.dk)
- Gianluca Barmina (gbarmina@imada.sdu.dk)
- Jacob Nielsen (jacn@imada.sdu.dk)
- Mogens Henrik From (from@imada.sdu.dk)
- Stine Lyngsø Beltoft (stinelb@imada.sdu.dk)
From the Department of Computer Science at the University of Copenhagen:
- Desmond Elliott (de@di.ku.dk)
From Center for Sprogteknologi at the University of Copenhagen:
- Bolette Sandford Pedersen (bspedersen@hum.ku.dk)
- Ali Basirat (alib@hum.ku.dk)
Project Alumnis
Lasse Hansen, Martin Bernstorff, Tao Tang
Core Contributors¶
Those without data access, but who have contributed substantially to the project including code contributions, model development, and experiment planning.
From Alvenir:
- Martin Carsten Nielsen (martin@alvenir.ai)
- Søren Vejlgaard Holm (swh@alvenir.ai)
Join Us¶
We invite collaboration and contributions from industry professionals, researchers, and the open-source community. Together, we can advance the field of Danish NLP and create a more inclusive digital future. You can reach out to us using the following channels:
| - DDSC Slack | Join the discussion in the "danish-foundation-models-text"-channel |
| - GitHub Discussion | Ask questions or start a discussion |
| - GitHub Issues | Noticed a bug in the code? Please create an issue |
| - Using the model? | If you use the model, let us know it makes it easier for us to apply for funding and justify the devopment of the project. |